

A Security incident handling and response plan is a premeditated plan on how you will determine, classify, and respond in an organized and prepared manner to a cyber attack that potentially impacts the business.
Your goal is to reduce the impact of the incident through containment, remediation, and prevention.
A cyber incident response plan equips and prepares people, tools, and processes to respond to a cybersecurity incident in the most efficient way to reduce the time of the incident, and or the data impacted by the incident. Recovering systems and data, and determining the root cause so that preventative measures can be implemented to reduce the risk of this incident happening again. This plan is really a framework of actions, processes, and resources. It includes the ‘when’ and provides guardrails and sometimes includes specific steps that need to be done.
When is a cybersecurity issue determined to be an incident? To answer this let’s look at how we can define this.
You need to define what “situation” impacts the business enough to be considered an “incident”. This is largely influenced by the companies security culture and their ability to identify high risk and high critical systems. This means given the resources of time, people, priority, and process to justify the cost of handling this issue in a high priority, escalated manner.
Examples of what can be used to get started to define a process for your company are:
- Data classifications (public / internal / sensitive / confidential)
- System Classification and applications (low / medium / critical)
- Number of records
- Source of the issue (mistake vs. external hacker)
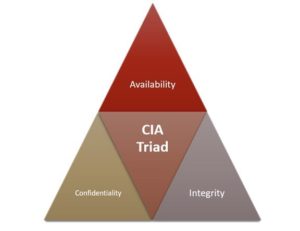
Cybersecurity focuses on three things referred to as the CIA triad:
- Confidentiality
- Integrity
- Availability
InfoSec Resources – InfoSec Institute
So a cyber issue needs to threaten either the availability, confidentiality, or integrity of assets to be considered an incident.
How it’s Discovered
An incident always starts with an ‘Alert’. The alert can come from a technology source or a user source.
From there it becomes a security event, and then it graduates to an investigation, and finally, it’s classified and determined to be an incident.
It’s important to call out that some incident plans include the ‘detection’ phase. When we look at the NIST Cybersecurity Framework we can see detection comes before containment. For this article, I feel an incident plan should begin at containment and separate strategies, tools, and tactics should already exist within a company environment to bring these detections to the surface to initiate the incident process. These strategies include security awareness training along with technical detection tools including; endpoint, network, and perimeter detection and alerting systems. Here are some common ways incidents can originate:
| Source: | |||
| Person report anomaly | Alert | Investigate | Incident |
| Endpoint Alert | Alert | Investigate | Incident |
| IT System Outage | Alert | Investigate | Incident |
| Outside Org (FBI) knocks on your door | Alert | Incident | |
| Firewall Alert | Alert | Investigation | Incident |
Not all alerts turn into incidents. But all incidents should include an alert of some type, either from a system or a person.
Alerts are classified as incidents after an investigation of an alert, or set of alerts provides reasonable evidence to indicate a significate threat is taking place or is imminent.
How to begin the incident process
I’ve never had two incidents happen the same way. But there is always a core group of task and actions that have complimented every incident. These actions are; escalation, logging, and evidence preservation (to be transparent, I haven’t performed evidence preservation in every incident I’ve ever handled). Here is a list of core activities:
Logging
- Source and time of the initial alert
- Time incident began
- Time to containment
- Time to remediation
- The time it took to begin incident (this might seem odd that this is later in the list, but typically you want to know this information when you start the incident process. It will require research to determine where the incident started, and how long it took a person, or system, to notice and then how long it took to notify you or someone in security.
- Escalation to leadership
- Document the chain of custody of any data or systems.
- Notification of Tiger Team (get to this later)
- Equip someone to lead and handle communication.
Preservation of Evidence
Going back to the statement of not always preserving evidence, I want to state it in this article and not overlook it as it can be critical. But it’s only critical if the business direction has the intention to follow through with criminal prosecution of the attacker. Sometimes the incident doesn’t involve an attacker. Sometimes the incident may involve an attacker, but the company has no intention of pursuing criminal action, then this measure can take less priority, and may even become optional.
Preserving evidence is often something I see in very mature cybersecurity organizations. It takes a significant investment from leadership to security personnel training to preserve evidence effectively. And oftentimes, even with these efforts, it still requires an outside origination to accomplish it effectively. With all this said, I also want to point out an opposing point that I recently heard a cybersecurity leader share he has never had a judge dismiss evidence from a cybersecurity case that was handled diligently by the company. This means, even without extensive training and certification a company can admit evidence by following basic protocols. It doesn’t have to be complicated.
Step 1 – Containment
The goal of containment is to contain the security incident impacted systems and prevent it from spreading to other systems and data, especially classified data and critical systems.
Containment includes:
| Isolation | Lockout / Disable Accounts | Redirect system traffic / DMZ | Collect IOCs |
Personal Story:
There was a malware infection that encrypted the endpoint at an organization. The user actually notified the security team before the malware detection engine escalated the alert. When console did escalate the alert it was a ‘malware infection spreading’ alert, and not an alert that the initial endpoint had been compromised. (A little late.) The alert was escalated to a security event and escalated to an incident. A computer security incident response team (CSIRT) was formed and determined the best course of action. The CSIRT team recommended a set of servers be disconnected from the network immediately. This was because the users’ endpoint that had been initially infected had rights to the servers. The risk owner (person who was ultimately responsible for the servers) said no, they should be fine. Within the hour the servers showed IOCs of being infected and the data began to be encrypted.
Threat Types
Containment requires some identification of what the threat is. Containment strategies and tactics are dependants on the threat vector and attack type.
Here are some common types of attacks:
- Malicious software / Virus / Malware
- Hacker accessing systems remotely
- Data exfiltration
- Ransomware / Encryption
- Software integrity / Code changes
The threat type can usually be determined by the symptoms and alerts that brought the alert to an incident classification. For example:
- Countdown Time on Screen = Ransomware
- High outbound traffic to foreign destination = data exfiltration
- Server accounts being created and disabled = Hacker
Based on the determined threat type, the next step can sometimes be a dance between two steps; isolation and collecting indicators of compromise. Before going further let’s stop here and discuss what an ‘indicator of compromise’ is.
IOCs
To contain a cybersecurity incident successfully, you need to know what you’re trying to contain. As you approach your investigation your goal is to find an indicator of compromise (IOC). IOCs are artifacts and evidence. They can be anything from an IP address, file hash value, filename, file date, URL, domain name, or folder location among other things.
A more mature cybersecurity program will have more resources to identify IOCs, such as Threat Intelligence, and tools to look for that IOC across the environment, such as file tools like Varonis, next-generation firewalls, and data flight recorders. But the process remains the same, even if the difficulty and capabilities change.
IOCs can be host based and network based. Each will have unique information that is specific to that source. Host-based IOCs will usually contain filenames and hash values. Network-based IOCs will usually contain IP addresses and domain names.
Your goal is to identify an ICO related t the incident and leverage the ICO to identify additional IOCs, and use all IOCs collected to identify the scope and proliferation of assets impacted by the incident.
It’s also worth mentioning that sometimes during the determination of IOCs you will find information that is unique about the impacted asset. This might be that the asset has a unique application installed, hasn’t been patched or has out of date software. This is important to note, as this can sometimes jumpstart the ‘prevention’ stage that we will take about later in this article.
Isolation vs IOC Discovery
If you believe IOCs can be discovered after the asset is isolated, then you should proceed with isolating the asset first and then try to collect IOCs. Then take those IOCs and leverage the available tools you have to search for the IOCs on other assets in your environment.
Example when isolation can happen first:
Malware infection on a workstation in the accounting department. Removing this system from the production network will not cause any additional impact. There are several other additional accounting workstations that images can be compared to. The alert was generated by endpoint protection software and the logs are in the central management console on the server. It can be isolated.
Example when IOCs should be determined before isolation:
User notifies helpdesk the YouTube video they are trying to watch is stuttering. Helpdesk hands the support ticket to the network team and they see the outbound traffic has saturated the available bandwidth. They don’t know the cause yet, but they notify security just in case. Cybersecurity can see the traffic is originating from a server containing manufacturing files. Security asks the network team how long outbound logs are retained for and the network team informs cybersecurity the logs are overwritten almost immediately. If the server is isolated, they will never know where the files were going, or prevent this source from accessing the network again. In this situation, there should be an allowance to capture logs and determine the destination IP address.
Containment Strategies
As a part of your cybersecurity incident handling and response plan, you can include a ‘playbook’ section that documents the containment strategies for the different threats you can imagine potentially happening against your environment. Here is a matrix you can use:
Malware:
- Isolate
- Gather IOCs
- Search assets for IOCs
- Perform system image of the infected system
Hacker:
- Determine IP address
- Blacklist IP on firewalls
- Reset all accounts on systems impacted
- Determine any additional logs or IOCs
Insider Threat:
- Collect and record as much activity as possible
- Escalate to leadership
- Support HR in the investigation
- After HR is done, remove access to systems
Denial of Service:
- Determine source IP (if you can)
- Create drop rule on perimeter firewalls
- Sinkhole traffic
- If you can’t (firewall overburdened), initiate carrier level DDOS tactics
Lost / Stolen Asset:
- Report to authorities
- Document what data, accounts, and access present on asset
- Validate encryption in the management console
- Blue Pill (remote wipe) if capabilities exist
- Reset user credentials
Step 2 – Remediation
The goal is no longer about stopping the attack, it is now about removing the residual impact and artifacts of the attack and getting the systems back to production status.
Remediation of assets impacted from an incident ranges from extremely simple to awfully complex. This depends on the remediation methodology you choose. There are essentially two ways to remediate:
- Remove malicious software/artifacts
- Clean system build or restore. (If restore, be sure to restore from before the incident timeline – as sometimes there is not confidence on when it was introduced.)
I feel the best way to proceed with the remediation of the cybersecurity incident handling and response plan is approaching the same attack vectors as we did with the containment strategies.
Malware: I’ve read other perspectives on the remediation of malware. These steps include removing the attack artifacts and deleting the rootkits. My experience has solidified my process of restore or rebuild from a known good state. Today’s malware is so advanced and complex, it’s extremely hard – let me say that again, extremely hard to be totally confident you’ve removed the malware infection or rootkit.
The only confident remediation direction I can provide is to save an image of the infected machine, and build a new endpoint or server and reinstall. Restore the data from backups. If there is critical data that was created or modified between the time of the previous backup and the cybersecurity incident then I recommend:
- Accessing the machine in a quarantined, separated environment
- Pull individual files off the infected image and directly upload them to a web interface of a sandbox and detonate them there to ensure they do not contain any part of the infection.
There are two situations that sometimes justify the removal of malware and reinstatement of the asset in production service. This includes the discovery that no backup exists or the software the system ran is no longer available. Ideally, these risks would have been discovered during a risk assessment previous the incident, and a risk acceptance would have documented. That risk acceptance document would have stated, “if system suffers from a malware infection there will be no ability to restore the system into service.” But in the real world, this often doesn’t happen and cybersecurity is tasked with removing the infection the best they can. Here are common remediation steps for malware and rootkit infection:
- Provide new, reimaged machine for the user.
Hacker:
- Blacklisting IP address
- Changing accounts to systems they had potential access
- Build Correlation Alert
Insider Threat:
- Work with authorities to remove all insider information and data from the threats of personal repositories. This is easier said than done, as it is extremely difficult to have the forensic data and logs to show a trail where all the information went because the data is often moved several times after it leaves your log sources. Authoritative legal presence, and the clear statement of legal consequences compliments this effort.
Denial of Service:
- Remediation is usually an immediate result of containment. If the Denial of Service was distributed, it can be harder to remediate as the source is from unmanaged and distributed endpoints across the Internet. This will require cooperation with your carrier and sometimes federal authorities.
Lost / Stolen Asset:
- There isn’t much you can do to remediate a lost or stolen asset unless the authorities can determine who stole it and help recover it.
- The only other option is to offer a reward for the recovered device. This can be helpful if the device contained sensitive or confidential data and the business wants greater confidence this risk was not exposed. If this case does happen, and a reward brings a device back, you’ll need to work with a forensic partner to determine if the data on the device was accessed, duplicated, or modified.
Step 3 – Prevention
Prevention has two primary goals:
- Prevent the same exploitation from happening to the same assets during the attempted incident recovery process.
This should be the priority focus. Use what you’ve learned, based on observation, logs, IOCs and wisdom, to determine what allowed this incident to take palace. Somethings to consider:
- Open inbound permissive channels
- Lack of employee training and awareness
- Out of date software/applications
- Unpatched security vulnerabilities
2. Prevent this, and similar attacks, from happening anywhere in the environment.
Use this moment as an opportunity to have something good come out of something bad. Evaluate the whole environment for relevant threat vectors:
- Weak passwords
- Missing patches
- Out of data applications
- Backdoors
Document the findings and propose remediation within a specific time frame. I’ve found thirty days to be a good balance of priority and business resources and leadership acceptance. A smaller timeframe, even when accepted by leadership, can burden teams, negatively impact relationships, and create a risk of production outages. On the flip side, it’s important to get leadership support while the iron is hot and before things cool down and priorities are taken over my other things.
Risk Acceptance
If the security findings you present are challenged by an inability to remediate, begin a ‘Risk Acceptance’ process and procedure. Either build a form, or complete a document, stating the business, or asset owner, wants to accept the risk of this security finding. You document the risk of not remediating this finding, and then give it to the asset ower to complete the justification and then sign. Then present the completed form to leadership for final approval and signatures (sometimes an email approval trail is acceptable – but the email retention policy needs to be adjusted so these documents are not lost). Now if there is an incident caused by this finding, you’ll have documentation the risk was identified by security and someone accepted the risk.
Prevention Techniques
Here are some common prevention techniques to address the risks we’ve covered.
Malware:
- Improve endpoint protection
- Improve user training and awareness to identify the threat
- Add additional preventive controls like file interrogation and sandbox.
Hacker:
- Determine how they were able to get a foothold into the system. Was this through remote access software, VPN, or a vulnerability in the web services?
- Remove footholds
Remote Exploit:
- Patch vulnerabilities on systems.
- Get approval for ongoing patch management process and ownership of responsibility.
Denial of Service:
- Contract for carrier level protection
- Move web facing assets to cloud provider that has security controls
- Add DNS Sinkhole technology and capabilities
To Serve & Protect
The last thing I want to point out and provide a reminder of is your role in all this. So far you’ve been the hero. The skills and knowledge you’ve built and exercised over the years have finally been put to the test and forged in a real cybersecurity incident. It’s easy at this moment to feel like an authority during an incident. Resist the urge to demand things get done like systems get patched immediately. Resist the urge to speak negatively and blame people or groups for the cause of this problem. Your role, as it always has been before you felt this power and excitement, is to serve your company and leaders. You can do this by staying calm, providing clear communication and facts. Do not get emotional, only positively excited. This is what combines your skills with character and separates those that ‘can do’ incident response and those that are ‘great‘ at incident response.
Step 4 – Post-Incident Review (PIR)
Post Incident Reviews are often overlooked in the exhaustion of the incident event. This review is important and should not be overlooked. The lesson learned should be shared across teams, including leadership and system owners. These company-specific exercises cannot be replicated outside your environment and are invaluable.
Pick a speaker to lead in a summary of the event and timeline. Then go around asking questions like:
- What did we learn from this event?
- What do you feel we did well?
- What do you feel we do better?
- Are there other areas this could happen we should discuss?
I’ve found the teamwork and comradery that happen during the stressful incident event create a team that is very vocal and transparent. This is a warm meeting with lots of great feedback. Someone should take notes and follow up with takeaways.
Congratulations and Summary
Scratch a numeral in your cubicle wall or get a tattoo, you’ve just made it through a cybersecurity incident! If you enjoyed the rush, could handle the stress and contributed to the containment, remediation, and prevention – this is the career for you. If you hated it, don’t sweat it there are other great roles in cybersecurity, but none like this one.
Thanks for reading. Please feel to share your tips on handling a cybersecurity incident and stories from your storm.
Recent Comments